
Podcast Transcription Pipeline and App
At 5:50, I say that all files are refreshed. In reality only the ones that have been flagged to be refreshed are refreshed.
At 14:15, I say that the model goes through about an hour’s worth of content in a few minutes. I am using a model optimized for speed available here: insanely-fast-whisper. The base model is much slower.
The following report has been written with the help of ChatGPT
Introduction
Explore how AI-driven transcriptions of German podcasts are being produced, stored, and used to help improve German language skills. This initiative shows how AI, cloud, and open source orchestration technology can enhance learning through precise transcription, data storage, and process automation.
In my journey of learning the German language, nothing has been as helpful as consuming German language content such as books, videos, and podcasts. One of the most helpful ways to learn useful everyday vocab, phrases, and sentence structure is hearing everyday conversation, and nothing is more filled with everyday conversation than long-form podcasts. The trouble is not a lot of podcasts come with subtitles, making it hard to tell what is being said.
As a solution, I have discovered whisper AI, an open source model developed and published by OpenAI. One can download this model, and run audio files through it, and have them transcribed.
The model, while imperfect, is very good at telling what is being said even in noisy environments, in colloquial phrases, anglicisms, unclear speech, and so on. Later on, I switched to another model optimized for speed, where the quality suffers somewhat, from my observations, but the gains in speed make it an attractive alternative.
The following is my attempt to automatically download, transcribe and parse podcast episodes using a data pipeline. I want a hands off approach, where all I have to do is add a podcast’s RSS link to my app, and receive the transcriptions for all episodes (new and exisiting) through a front end.
The standardization that exists in the world of podcasting makes this process possible. At the heart of the system is the RSS file. An RSS file is a standardized set of metadata about the podcast and its episodes. It contains information such as the podcast and epside titles, descriptions, publish dates, and most crucially links to the .mp3 files of the podcast episodes themselves.
The goal of this project is to set up an automatic process that would parse these RSS files, refresh them daily to look for new episodes, store the episode and podcast data in a relational database, transcribe the episodes, for a given podcast. Everything revoles around the RSS files.
Technical Overview - Cloud Setup
The parsing of the RSS file will be done on Azure with the use of Function Apps; the storage of the data will be done on Azure Container Blob Storage; the storage of the podcast and episode metadata will be on a Azure-hosted relational database; and the transcription will be done using whisper AI on my local machine because of cost concerns (it is far cheaper to run these models locally than on the cloud).
For reference, here is what a sample RSS file might look like:
<rss>
<channel>
# This is the podcast-level information
<title>PODCAST TITLE</title>
<language>de</language>
<pubDate>Mon, 12 Oct 2020 10:52:11 +0000</pubDate>
<description>
Podcast description would go here.
</description>
<link>https://link-to-the-podcast.com</link>
...
More potential podcast-level info here.
...
# Here is the episode-level information. Each episode is considered its own item.
<item>
<title>Most recent podcast episode</title>
<description>
Episode description.
</description>
<pubDate>Thu, 13 Jun 2024 15:30:00 +0000</pubDate>
...
More potential episode-level info here.
...
<enclosure url="https://most_recent_podcast_episode.mp3?source=feed" type="audio/mpeg" length="74689861"/>
</item>
<item>
<title>Another podcast episode</title>
<description>
Episode description.
</description>
<pubDate>Wed, 12 Jun 2024 15:30:00 +0000</pubDate>
...
More potential episode-level info here.
...
<enclosure url="https://another_podcast_episode.mp3?source=feed" type="audio/mpeg" length="74689861"/>
</item>
</channel>
</rss>
Object (Blob) Storage
The relevant files for this project will in part be stored in an Azure Blob Storage account with the following structure:
Storage Account
├── xml
│ ├── podcast1_rss_feed.xml
│ ├── podcast2_rss_feed.xml
│ └── ... (more RSS feeds)
├── mp3
│ ├── podcast1
│ │ ├── episode1.mp3
│ │ ├── episode2.mp3
│ │ └── ... (more episodes)
│ ├── podcast2
│ │ ├── episode1.mp3
│ │ ├── episode2.mp3
│ │ └── ... (more episodes)
│ └── ... (more podcasts)
└── transcriptions
├── podcast1
│ ├── episode1
│ │ ├── episode1.txt
│ │ └── episode1.srt
│ ├── episode2
│ │ ├── episode2.txt
│ │ └── episode2.srt
│ └── ... (more episodes)
├── podcast2
│ ├── episode1
│ │ ├── episode1.txt
│ │ └── episode1.srt
│ ├── episode2
│ │ ├── episode2.txt
│ │ └── episode2.srt
│ └── ... (more episodes)
└── ... (more podcasts)
-
In the XML container exist the RSS Feed files for each episode. In my quest for finding podcasts to listen to I looked for podcasts on various topics - conversation, science, religion, tech, and stored the RSS files in this container. The process for how these are refreshed and parsed for new episodes is described below.
-
In the mp3 container are the mp3 files for the podcast episodes.
-
Finally in the transcriptions container are the episode transcriptions. They come in two formats .srt files and .txt files.
The .srt format is specific for subtitles. Below is a sample .srt file generated by ChatGPT to show representation of what the contents of an .srt file might look like:
1
00:00:00,000 --> 00:00:04,000
[Intro Music]
Colorado is a great place for travelers.
2
00:00:04,001 --> 00:00:08,000
From the Rocky Mountains to the Great Sand Dunes, there's something for people with various interests.
...
The .txt file contains all the same transcription data, just without the timestamps.
Azure SQL Server
The SQL Server component is comprised of several tables. They are used to keep track of the processing of the RSS files and also the individual episodes.
-
Table 1: rss_urls
- Contains the podcast level information and the URL of the podcasts’ RSS files.
- Table structure:
Column Name Description Data Type Nullable podcast_name Name of the podcast nvarchar not null rss_url URL of the podcast RSS feed nvarchar not null daily_refresh_paused Indicates if daily refresh of the RSS file is paused varchar null last_parsed Date the podcast was last parsed date null podcast_id Unique identifier for the podcast int (Primary Key) not null (click to zoom in)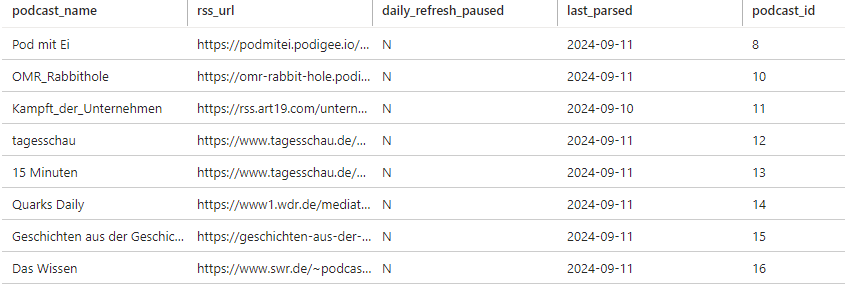
- Details:
- If the field daily_refresh_paused equals ‘Y’, then the RSS Feed for that podcast is not parsed. This allows for easy management of processing the podcasts.
- podcast_id is there to work with the front end of the app, which expects a primary key. Otherwise it is not used.
-
Table 2: rss_feed
- Contains the episode level information. Serves (aspirationally) as the single source of truth on the status of the processing of the episodes.
- Table structure:
Column Name Description Extracted from the RSS File? Data Type Nullable id Primary key No int not null title Episode title Yes nvarchar not null description Episode description Yes nvarchar null pubDate Publication date of the episode Yes datetime null link URL link to the episode mp3 file Yes varchar null podcast_title Title of the podcast Yes nvarchar null language Language of the podcast Yes nvarchar null parse_dt Date when the feed was parsed, and the episode was added to this table No datetime not null download_flag_azure Indicates whether the episode mp3 was downloaded to Azure blob storage No char not null download_dt_azure The datetime when the episode mp3 was downloaded to Azure blob storage No datetime null transcription_dt Transcription completion date No datetime null transcription_location Location of the transcription file No nvarchar null download_flag_local Indicates whether the episode mp3 was downloaded to my local machine, to be transcribed No char not null download_dt_local The datetime when the episode mp3 was downloaded to my local machine No datetime null nouns_extraction_flag Flag for noun extraction status No varchar null nouns_extraction_dt Noun extraction completion date No datetime null schon_gehoert_flag Indicates whether I already listened to the episode No varchar null verbs_extraction_flag Verb extraction status flag No varchar null verbs_extraction_dt Verb extraction completion date No datetime null (click to zoom in)
- Details:
- The id field is there to work with the front end of the app, which expects a primary key. Otherwise it is not used.
- The transcription_dt really indicates when the transcription was uploaded to Azure blob storage, rather than when it the file was actually transcribed. The same is true for the fields nouns_extraction_dt and verbs_extraction_dt. For all intents and purposes, this is an unimportant distinction.
Azure Function Apps
The next step is to explain the function apps. There are three in total:
- The rss_refresh_daily script refreshes the RSS files, by downloading the RSS file again.
- The reading_in_rss_and_writing_to_sql script parses the RSS Files and extracts useful information.
- The mp3_download script downloads the mp3 episode files and stores them on Azure blob storage.
The code for all three functions is available here: Code for the RSS Function App
1. rss_refresh_daily Function App
This function runs every day at 3:00 AM
It looks in the rss_urls table to find each podcast’s RSS URL link. It then follows that link and downloads the RSS XML file anew, effectively refreshing the RSS Feed file everyday. If a podcast has the daily_refresh_paused flag set to ‘N’, that podcast’s XML file does not get refreshed.
Below is the query that finds the podcasts to be refreshed:
SELECT podcast_name, rss_url
FROM dbo.rss_urls
WHERE daily_refresh_paused = 'N'
The XML files get written into the xml container on the Azure Blob Storage Account, with versioning enabled, so the files can be later analyzed for differences, if desired.
2. reading_in_rss_and_writing_to_sql Function App
This function runs every 20 minutes.
It selects a random RSS Feed file from the xml container and parses it, item by item. Each item in the file represents a podcast episode and some metadata. The function then looks to see if that particular episode along with its metadata exists in the rss_schema.rss_feed table, and if not, it inserts it.
Below is the query that inserts the parsed data into the rss_schema.rss_feed table. It also shows some of the episode level metadata that is gathered.
insert_query = text("""
INSERT INTO rss_schema.rss_feed (
title,
description,
pubDate,link,
parse_dt,
download_flag_azure,
podcast_title,
language)
VALUES (
:title,
:description,
:pub_date,
:enclosure_url,
GETDATE(),
'N',
:podcast_title,
:language)
""")
conn.execute(insert_query, {
'title': title,
'description': description,
'pub_date': pub_date,
'enclosure_url': enclosure_url,
'podcast_title': podcast_title,
'language': language
})
3. rss_refresh_daily Function App
This function runs every 20 minutes
It looks for the most recent not-yet-downloaded episode in a randomly chosen podcast and downloads the episode into the Function App’s temp storage. It then uploads the file to the mp3 storage account. If no such episode is found (when there are no new episodes for a chosen podcast), the script does nothing.
Once an episode is downloaded, the appropriate flags in the rss_schema.rss_feed table get updated:
UPDATE rss_schema.rss_feed
SET download_flag_azure = 'Y', download_dt_azure = GETDATE()
WHERE id = {episode[0]};
This function can easily be scaled up to run more often and download more episodes. Because the bottleneck for me was the transcription process (to be described below), I didn’t need this app to be more efficient than it was. If this project were to take on a more Production-level approach, it would be need to be cleaned up and optimized.
Technical Overview - Local Setup
Now we’ll dive into the local setup. As I mentioned before, it is effectively free to run open source models locally, disregarding the cost of the computer and utilities.
To orchestrate this process, I used another open source tool called Airflow. This tool allows the user to schedule scripts to run on an interval. This is useful for this project because I wanted to regularly pull down the newly downloaded episodes from Azure Blob Storage, transcribe them, and parse them for nouns and verbs. Everything but the transcription will be run by Airflow inside a Docker container. The following sections will go into the setup of each.
Docker
Airflow is running on my local Linux machine within a Docker container. This section will delve into the Docker container setup, and the next section will continue with the Airflow setup.
- The
Dockerfileis available here: Dockerfile
A version explaining the file in detail is shown below.# Downloading this version of Airflow # This provides a pre-configured environment for running Airflow. FROM apache/airflow:2.9.3 # Set the timezone environment variable # This ensures timestamps and logs are in the correct timezone. ENV TZ=Europe/Berlin # Add root user if it's missing RUN echo "root:x:0:0:root:/root:/bin/bash" >> /etc/passwd # Install git and other dependencies USER root RUN apt-get update && apt-get install -y git && apt-get clean # Switch back to the airflow user USER airflow # Install the additional Python packages # A library used to interact with Azure Blob Storage RUN pip install azure-storage-blob # A library for managing environment variables using .env files RUN pip install python-dotenv # A library for working with databases in Python # and for connecting to MS SQL Server databases, respectively RUN pip install sqlalchemy pymssql # Updates pip, setuptools, and wheel to their latest versions RUN pip install -U pip setuptools wheel # NLP library used to identify German verbs and nouns RUN pip install -U spacy RUN python -m spacy download de_dep_news_trf # Used to work with dataframes in Python RUN pip install pandas -
The
docker-compose.yamlfile is available here: docker-compose.yamlAn important part of the file to call out is the
volumessection, which mounts directories from the host system onto the container. This allows the container to access files from the host system, making it possible to share data between the host and the container.volumes: ..... - /home/maksym/Documents/whisper:/home/maksym/Documents/whisper .....The line above mounts the directory
/home/maksym/Documents/whisperfrom the host to the same path inside the container. This would allow the scripts to be triggered and run insideDockerbyAirflow. The benefit of keeping the path the same is when doing development directly on the host machine, no file paths would need to be changed.
Airflow
In order to keep the orchestration scripts separate from the processing scripts, I had the following structure:
airflow_docker/
├── dags/ # contains the orchestration scripts
└── external_scripts/ # contains the data processing scripts
Each DAG (Directed Acrylic Graph, or in other words ‘Orchestration Job’) was used only to trigger each processing script. The main scripts will be shown below.
to be continued…